1. Razonamiento Computacional¶
Contenidos¶
- Introducción a la Programación.
- Modelación.
- Evolución del Método Científico.
- Programas, Lenguajes y Compiladores.
- Asuntos Éticos en la Informática.
- Hardware: Los “Fierros” del Computador.
- Algoritmos.
- Depuración (“Debugging”) de rogramas.
- Resumen-Glosario.
- Referencias.
1.1 Introducción a la Programación¶
El objetivo de este libro electrónico interactivo, llamado Py-Libre, es el de apoyarte en el aprendizaje de los conceptos básicos de la programación computacional para modelar y resolver problemas en ingeniería, matemática y ciencias básicas. Utilizaremos el lenguaje Python como base para demostrar los conceptos y generar la interpretación y solución de problemas. Esperamos que este libro sea una herramienta útil y entretenida para todos los estudiantes del curso de introducción a la programación, facilitándoles la inmersión en la belleza del “razonamiento computacional” el cual es hoy día un requisito sine qua non para comprender, avanzar e innovar en las ciencias y tecnologías.
El énfasis del libro está más en el “aprender haciendo” que en el desarrollo conceptual o teórico (Maloy et al., 2014). Para estos efectos se cuenta con una herramienta interactiva que permite probar directamente (desde el mismo libro-electrónico que se accede por la Web) diversos programas y visualizar los resultados de su ejecución (Miller, Ranum, 2016). Se presentan dos modalidades de ejercicios interactivos: programas incompletos que se pueden rellenar y luego ejecutar o simplemente un espacio para escribir un programa nuevo y probarlo, todo esto sin salir del Py-Libre. Por consiguiente, necesitas un computador con Internet para conectarte al sitio Web y poder disfrutar de la programación mientras lees el libro.
El razonamiento computacional utiliza las herramientas de programación primero para entender una cierta situación de ingeniería, ciencia o gestión, representarla en un modelo abstracto computacional (un programa escrito en Python u otro lenguaje) y luego resolverla entregando las soluciones alcanzadas. Dicho razonamiento está fundamentado en la matemática, en la modelación (ingeniería) de sistemas y en la tecnología computacional. A medida que avancemos en el libro, iremos descubriendo los distintos mecanismos que nos permitirán pensar (resolver problemas) en forma computacional.
Podemos decir que un programa computacional (también conocido como “aplicación” o “software”) puede servir al menos para cuatro tipos de actividades:
- Almacenar, ordenar y buscar datos (por esto que en algunos países el “computador” se conoce como “ordenador”). Cuando los datos son masivos se habla de “Big Data” y minería de datos.
- Modelar o representar diversas situaciones. Por ejemplo un programa para representar la estructura de un puente y las cargas que debe resistir, otro para “simular” el tráfico de vehículos en una intersección, u otro para una situación de combate en un juego de Star Wars.
- Resolver problemas de cálculo matemático con mucha rapidez y eficiencia (por eso que en otros países el “ordenador” se conoce como “computador”).
- Comunicar a personas (“usuarios”) entre sí y con el computador. Esta actividad da origen a las redes sociales informáticas.
En este libro veremos la representación de diversos problemas los cuales podrán clasificarse en alguna de las cuatro categorías anteriores o mezcla de ellas. Partiremos con problemas básicos de matemática y luego iremos aumentando la complejidad para comprender la utilidad de la programación en ingeniería y ciencias. Antes de comenzar, daremos una breve mirada a algunos fundamentos de la programación computacional, tales como modelación, el método científico, informática y ética, programas, lenguajes, compiladores-intérpretes, hardware o “fierros”, y algoritmos.
1.2 Modelación¶
La actividad de modelación está intrínsecamente asociada al pensar. Cada vez que pensamos construimos en nuestra mente una representación (modelo) de la situación lo más cercana a la realidad posible. A través de nuestros sentidos percibimos información que nos sirve para consolidar nuestros modelos mentales. Esta información pasa por el “filtro” de nuestros modelos mentales. Nuestra mente funciona en base a modelos; no funciona en base a “realidades” (para bien o para mal). Pero (por suerte) no es objetivo de este libro filosofar con respecto a la capacidad (o incapacidad) de nuestras mentes para alcanzar la “realidad” más allá de los modelos que nos auto-imponemos.
En forma similar a la mente humana, con un programa computacional construimos un “modelo virtual” de una situación, le entregamos información de “entrada” para consolidarlo, resolvemos (procesamos) el modelo y generamos una solución que llamamos la “salida” o resultado del programa. Este proceso de “programación” lo podemos representar como un “sistema” tal como se muestra en la figura 1.1. Así entonces podemos resolver muchos problemas complejos de la matemática, ingeniería y ciencias, en forma matemáticamente exacta o aproximada. Desde los inicios de la computación se ha bautizado a este proceso como “inteligencia artificial” (IA) porque intenta asemejarse al pensamiento humano racional. Claro que es mucho más fácil entender y construir “inteligencia artificial” que “inteligencia humana” (por suerte de nuevo para los que escribimos este libro).

Existen muchos tipos de modelos para representar situaciones de la ingeniería y ciencias exactas (incluyendo la economía y finanzas, aunque últimamente no han estado muy “exactas”). Los podemos clasificar primero como modelos “físicos” o modelos “matemáticos” (ver figura 1.2). Por ejemplo, las maquetas que construye un ingeniero para representar un puente o un arquitecto para un edificio, son modelos “físicos”. Estos modelos pueden ser estáticos o dinámicos. Las maquetas “físicas” generalmente son estáticas puesto que no alcanzan a representar el movimiento (por ejemplo, sísmico) o el transcurso del tiempo. Pero si construimos un “drone” o pequeño avión de juguete controlado por radio, tendremos un modelo físico dinámico.
Por otro lado, aquellos modelos que se construyen solo con fórmulas y ecuaciones, típicamente en un programa computacional (antiguamente en papel y lápiz), se conocen como modelos matemáticos. Estos también pueden ser estáticos o dinámicos, dependiendo si representan situaciones con o sin movimiento o transcurso del tiempo. Los métodos (programas) de optimización (por ejemplo Simplex) y el conocido “Monte-Carlo” (con representación de situaciones aleatorias) son modelos matemáticos estáticos, porque encuentran una solución de “equilibrio” en forma independiente del tiempo o de movimientos específicos de los elementos participantes.
Los programas de “simulación” que representan situaciones de movimientos y transcurso del tiempo son ejemplos de modelos matemáticos dinámicos. Por ejemplo, para representar la congestión en una autopista a ciertas horas de tráfico “punta”, el encolamiento en la oficina de espera de un hospital, o la atención de un conjunto de cajeros en un banco. En la figura 1.2 se esquematizan los diversos tipos de modelos que hemos mencionado.
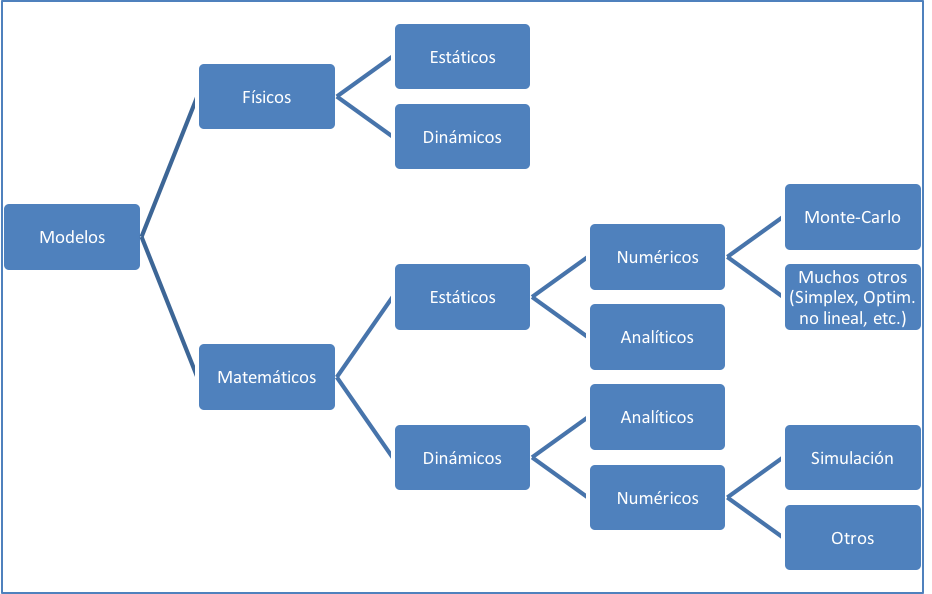
Cabe mencionar otra diferenciación de los modelos matemáticos, esto es en “numéricos” y “analíticos”. Los modelos analíticos se construyen en base a fórmulas y ecuaciones que permiten encontrar soluciones por resolución matemática, ya sean estáticas o dinámicas. Por ejemplo, ecuaciones para determinar largos de cola promedio, tiempos de respuesta promedio (por ejemplo, tiempo de espera en la cola y atención en el cajero), etc. Cuando las soluciones matemáticas son muy complejas o simplemente aún no se han descubierto, se utilizan métodos numéricos que van probando diversos valores para las variables del modelo, muchas miles de veces con generadores de números aleatorios, hasta encontrar una solución aproximada. Para esto los programas computacionales son muy útiles.
Además de los modelos de ingeniería y ciencias exactas recién mencionados, la programación computacional ha expandido la aplicación de modelos “sociales” que intentan representar el comportamiento y comunicación de los seres humanos más allá de los razonamientos “matemáticos”. Por ejemplo, en los programas llamados “tutores inteligentes” se utilizan modelos de “aprendizaje” para representar el comportamiento de un estudiante cuando está intentando aprender nuevas materias de lenguajes, matemática, historia u otras disciplinas (Woolf, 2008). En forma personal o colaborativa con otros estudiantes. También para simular una cirugía o situaciones de enfrentamientos culturales, sociales o militares. Los juegos de video que han permitido crear un nuevo y espectacular medio de entretenimiento, son también un buen ejemplo de estos modelos. Para estos modelos computacionales la forma como interactúa un “usuario” con el programa computacional o con otro “usuario” (disciplina conocida como “interfaces o interacciones humano-computador”, IHC) es de vital importancia. La comunicación a través de redes sociales (como WhatsApp y FaceBook) requiere de sofisticados programas de IHC.
Es importante destacar finalmente que en la programación computacional siempre estaremos modelando o representando situaciones del mundo real o de un universo ficticio o de conceptos abstractos (como la matemática). Sea para almacenar, curar y buscar datos, hacer cálculos matemáticos, entretener o comunicar en redes sociales. Por esta razón, todos los lenguajes de programación poseen algún modelo básico desde el cual se construyen las herramientas que permiten a su vez crear nuevos programas y modelos más sofisticados.
En nuestro caso, el lenguaje Python se basa en el modelo de “objetos” también llamado “programación orientada a objetos”. Esto se refiere a representar el mundo real o ficticio, se trate de una situación social o de en un problema de matemática-ingeniería, con objetos y la interrelación entre ellos. Todas las cosas que queremos representar en un programa las consideraremos como objetos: un auto, un cliente, un estudiante, un profesor, un número entero, un número complejo, etc. Sobre estos objetos construiremos luego modelos analíticos o de simulación o sociales. Pero no te preocupes puesto que iremos desarrollando estos conceptos poco a poco, sin sufrimiento y a medida que avanzamos en la materia sin olvidarnos del gusto de aprender.
1.3 Evolución del método científico¶
En el libro “El Cuarto Paradigma” (Hey, et al., 2009), se describe la forma en que ha ido evolucionando el método de descubrimiento científico a través de los siglos, estando los últimos avances fuertemente ligados a la computación. Se reconocen cuatro etapas o paradigmas tal como se ilustran en la figura 1.3.
El primer paradigma se refiere a la ciencia empírica que comienza hace más de mil años atrás la cual se centra en la descripción de fenómenos naturales. Luego, hace unos pocos cientos de años atrás, comienza la ciencia teórica con Kepler, Newton, Maxwell y otros grandes científicos (segundo paradigma). Posteriormente, muchos de los nuevos modelos teóricos (matemáticos) se hicieron demasiado complicados para ser resueltos analíticamente (fórmulas y ecuaciones cerradas) y nace la ciencia computacional con el uso de modelos de simulación (tercer paradigma).

Hoy en día los modelos de simulación y la ciencia experimental están generando enormes cantidades de datos (“Big Data”) que requieren nuevas herramientas para poder procesarlos. Por ejemplo, los astrónomos ya no “miran” por los telescopios sino que “exploran” en sus computadores los millones de datos que se capturan a través de los complejos instrumentos de observatorios tales como Cerro Paranal, La Silla y Las Campanas en Atacama, Chile. Nace entonces la llamada “Ciencia-e” (“e-Science”) que se vale de programas computacionales para capturar, curar/procesar/almacenar datos (“Bases de Conocimiento”, KBS), y luego explorarlos con métodos de minería de datos y otros afines al “Big Data”.
Ciertamente las herramientas computacionales primero para la simulación y luego para la e-Ciencia han debido sofisticarse al extremo para poder ser de verdadera utilidad tanto en la capacidad de cómputo (poder procesar millones de instrucciones por segundo) como en las soluciones (programas) para ordenar, almacenar, curar y explorar las enormes cantidades de datos que se generan minuto a minuto en todo el mundo. Una característica fundamental de los computadores para poder transformarse en la gran herramienta que son hoy para la ciencia es la velocidad de procesamiento.
La velocidad de procesamiento (medida en ciclos “GHz” o en miles de instrucciones por segundo “mps”) es una característica del procesador (o procesadores) de un computador. Es un atributo del “hardware” o “fierros” del equipo, a diferencia del software o programas computacionales. La velocidad depende del número de transistores en un chip de procesamiento y ha ido creciendo en forma exponencial en las últimas décadas. La Ley de Moore establecida en los años 70s del siglo pasado, establece que la velocidad de un procesador secuencial (un paso a la vez) se duplica (por el avance en la fabricación de chips) cada dos años. Esto es un crecimiento de velocidad del 40% por año (Mack, 2015).
A comienzos del siglo XXI se alcanza un límite a la Ley de Moore (aproximadamente en los 3 GHz) por un problema de sobre-calentamiento del procesador por la cercanía de los transistores entre sí. Este requiere mecanismos de enfriamiento cada vez más grandes y poderosos, haciendo impracticable la construcción de computadores más veloces. Pero la Ley de Moore se logra extender con la nueva tecnología de procesadores “multi-core” que básicamente van duplicando la cantidad de procesadores independientes en un chip, cada dos años. No obstante, no se logra sacar el máximo de “velocidad” del procesador “multi-core” si no se opera con software (programas) que realicen operaciones simultaneas (computación paralela o paralelismo) a diferencia de las operaciones secuenciales, un paso a la vez, de los computadores con un solo procesador. Si bien la computación paralela es un área muy importante, no la cubriremos en este libro.
1.4 Asunto éticos en la informática¶
Utilizaremos aquí el concepto amplio de informática o tecnologías de información y comunicaciones (TIC) para referirnos a todos los dispositivos de hardware y software como computadores personales, tabletas, teléfonos celulares, redes computacionales, mega sistemas de almacenamiento y procesamiento digital, procesadores embebidos (por ejemplo en automóviles, lavadoras, y elementos de seguridad), entre otros, junto con los procesos y políticas asociadas para su desarrollo y utilización. Pero, ¿qué tiene que ver la ética con las TIC? Muchas personas se podrán sentir sorprendidas porque nos refiramos a la ética en un libro sobre tecnología computacional.
Para nosotros es un tema de vital importancia dado el impacto que las TIC está teniendo en las personas y en la sociedad, a nivel mundial. Los computadores (“hardware”) y los programas que operan en ellos (“software”) son hoy en día una herramienta fundamental no solo para las ciencias y los negocios sino que también para la comunicación social, la educación, el transporte, el entretenimiento y la vida personal. Están contribuyendo a mejorar la calidad de vida de las personas y ya no es posible visualizar a un mundo sin teléfonos celulares, computadores, Internet, y redes sociales tales como Facebook y WhatsApp. Pero también pueden contribuir a generar más injusticia y desigualdades si son mal utilizadas o diseñadas con falencias.
Diversos autores (Steen, Van de Poel, 2012) indican enfáticamente que las TIC no solo reflejan los valores de la sociedad sino que también contribuyen a darles forma. Es decir, son herramientas y procesos cuyo impacto ético dependerá de su diseño y de su uso. Por ejemplo, hemos conocido en 2015 el uso incorrecto de software por los fabricantes de prestigiosos automóviles para falsear la medición de emisiones de gases que deterioran el medio ambiente. También conocemos el cuestionable uso de software de minería de datos en redes sociales para obtener perfiles psicológicos de los usuarios y luego venderlo a terceros para fines no consultados con las personas afectadas. Además del empresario y del gerente comercial, ¿tienen algo que decir en estas prácticas los desarrolladores del software y gestores de las TIC? Nosotros pensamos enfáticamente que sí.
En general podemos mencionar cuatro grandes ámbitos donde las TIC pueden tener impactos éticos en las personas y sociedad. Estos son: privacidad, propiedad intelectual, acceso a la información e integridad de los datos. Si bien las TIC también pueden incidir en comportamientos adictivos (por ejemplo, los video-juegos), este es un tema de otro ámbito al cual no nos referiremos en este libro.
La privacidad en informática tiene relación con las formas en que se colecciona, almacena y disemina la información sobre los individuos (clientes, empleados, usuarios) y sobre las organizaciones. Por ejemplo, algunas preguntas éticas sobre privacidad son:
¿Qué información sobre el individuo (u organizaciones) se debe revelar a otros? ¿A quiénes se puede/debe revelar? ¿Qué tipo de control y vigilancia (de las actividades informáticas) puede ejercer un empleador sobre sus empleados? ¿Qué información puede un individuo (organización) mantener para sí, y no ser forzado a revelarla?
¿Qué información sobre individuos se puede mantener en una base de datos (en qué organización), y cuan segura está la información allí? ¿Podemos/debemos registrar los patrones de uso de los recursos tecnológicos (especialmente Internet) de nuestros empleados o de nuestros alumnos en la universidad? ¿Para qué fin, con qué criterio?
Los asuntos de propiedad en informática tienen relación con los derechos de autoría y el valor de la información, contenidos multimedia, programas y aplicaciones de software. También tiene relación con el uso de recursos informáticos de la organización para fines personales (e. g., el correo-e). Algunas típicas preguntas éticas relativas a la propiedad informática son las siguientes:
¿Quién es el dueño de la información y de los canales de distribución? ¿Cuál es el justo valor en la comercialización? ¿Cuándo debe ser libre para todos? ¿Cómo se debe perseguir y multar la piratería del software (uso ilegal de licencias de productos informáticos), de la información y de los productos en medios informáticos (música, vídeo, multimedia educativo, etc.)? ¿Cómo se pueden utilizar las bases de datos propietarias? ¿Se debe pedir autorización a los individuos cuyos datos están en dichas bases? ¿Se pueden utilizar para fines personales los computadores y otros recursos tecnológicos que pertenecen a la organización empleadora?
¿Puede/debe una empresa poner límites a esta utilización personal de sus recursos? ¿Son dueños de la información los expertos que colaboraron en la creación de un sistema experto o de apoyo a la toma de decisiones? ¿Quién es el dueño del software (código fuente/objeto)? ¿Es dueño de la información /programas el desarrollador contratado por un tercero?
Los asuntos de accesibilidad informática tienen relación con el derecho a acceder a la información y la necesidad/justicia de pago por ello. La desigualdad en el acceso a la información a generada la llamada “Brecha Digital” (“Digital Divide”) entre grupos sociales y entre naciones. Algunas preguntas típicas respecto a la accesibilidad son:
¿Quién está autorizado a acceder… a qué información? ¿Cuánto cuesta dicho acceso? ¿Qué obligaciones de acceso se tienen con los empleados / usuarios con limitaciones físicas? ¿Qué obligación tiene el empleador de proveer equipos y recursos computacionales para sus empleados? ¿Se puede/debe filtrar el acceso o limitar los horarios de uso? ¿Sobre qué información tienen derecho de acceso los individuos y las organizaciones? ¿Con qué limitaciones?
La “Brecha Digital”: ¿Cuáles son nuestras responsabilidades, como ciudadanos, empresarios, universitarios y gobierno, para permitir/facilitar el acceso a las tecnologías a toda la ciudadanía? (La desigualdad de oportunidades que esto genera es preocupante.)
¿Qué recursos informáticos en la Intranet de una organización (por ejemplo, en una universidad) deben requerir autenticación para su acceso? ¿Se puede/debe filtrar la información que entra/sale por Internet en una organización o un país? ¿Quién lo debe/puede hacer? ¿Qué criterios se utilizan?
Finalmente la integridad de los datos tiene relación con la autenticidad, fidelidad y exactitud de la información recolectada y procesada en los sistemas. Algunas de las preguntas relativas a la integridad son típicamente las siguientes:
¿Quién es el responsable de la autenticidad, fidelidad y exactitud de la información recolectada? ¿Cómo podemos asegurar que la información será procesada apropiadamente y presentada a otros en forma exacta?
¿Cómo podemos asegurar que los errores en las bases de datos, en la transmisión y en el procesamiento de la información son accidentales y no mal intencionados? ¿Quién es el principal responsable de los errores en la información (su almacenamiento, procesamiento y transmisión), como se deben remediar y como se debe compensar a los afectados?
Lamentablemente, el crecimiento explosivo de la información y del conocimiento, el aumento sostenido de las capacidades de transmisión multimedia de las redes informáticas, el cambio acelerado de las TIC, la presión por la eficiencia y los resultados… no dejan a los encargados de la gestión informática mucho tiempo para pensar y discutir los asuntos éticos recién discutido. Así es entonces que nos encontramos llenos de situaciones donde las TIC atentan contra la ética y los derechos de los ciudadanos. Se debe entonces tomar una mayor conciencia de su importancia para ponerla en la agenda de la gestión informática.
Más aún, las decisiones relativas a la ética en el trabajo (ya sea privado o estatal) y en el ámbito social, serán un resultado de la reflexión personal que podamos hacer cada uno de nosotros. ¿Qué mejor que comenzar a hacer dicha reflexión cuando estamos estudiando y formándonos para ser profesionales socialmente responsables, emprendedores e innovadores? Debemos preguntarnos aquí y ahora cual es nuestra posición personal frente a lo correcto o incorrecto en las actividades como estudiante y miembro de una sociedad que requiere nuestro accionar para mejorarla y otorgar mayores y mejores oportunidades a aquellos que tienen menos. Nuestra responsabilidad como “aprendices” de las TIC es conocer, discutir y pensar sobre estos asuntos y reflejarlo en nuestras acciones y prácticas diarias.
El problema de la “copia” o plagio de los trabajos y exámenes es una pandemia que desgraciadamente azota a todas las instituciones educacionales del mundo. Nace de una actitud personal irreflexiva que busca alcanzar un cierto objetivo (“ser exitoso”, obtener un título profesional, maximizar las utilidades, etc.) sin importar los medios que se emplean. No se reflexiona sobre el daño a los demás y a sí mismo. Las TIC entregan poderosas herramientas para controlar el plagio (tales como software que pueden comparar miles de documentos y determinar la similitud entre ellos tanto en contenidos como en estructuras). O se pueden poner cámaras en las salas de clase para grabar todas las actividades que realizan los estudiantes durante un examen. Pero también pueden facilitar la actitud tramposa y desleal por la facilidad de acceder y compartir información entre dispositivos.
Debemos entonces re-pensar y re-definir las pautas y referencias que utilizamos para decidir nuestro accionar tanto en nuestros estudios como en nuestra actividad profesional. Ciertamente el principio del “exitismo” tan en boga hoy en día nos llevará siempre a tomar decisiones incorrectas, irresponsables y carentes de ética. Pero podríamos adoptar otro antiguo principio que dice “trata a los demás como te gustaría que te trataran a ti mismo y disfruta la belleza de hacer las cosas bien”. No te olvides que los que copian hoy como estudiantes son los que posteriormente hacen trampa como empresarios, empleados privados o funcionarios públicos. Tu responsabilidad es pensar y decidir aquí y ahora para que juntos podamos construir una sociedad más justa y transparente.
1.5 Programas, lenguajes y compiladores¶
Los programas computacionales (software) se escriben en un cierto lenguaje formal (por ejemplo Java o Python) y consisten básicamente en instrucciones que deberán ser ejecutadas por el procesador (CPU) del computador. Dichas instrucciones pueden ser acciones muy simples como por ejemplo leer algunos datos, hacer algunas operaciones aritméticas sobre los datos y luego escribir el resultado típicamente en la pantalla del computador. Veamos un ejemplo (verás en los próximos capítulos que este es un ejemplo muy sencillo).
Un programa funciona tal como lo esquematiza el ejemplo 1.1, con datos de entrada, procesos y datos de salida (o resultado). Supongamos que queremos transformar a kilómetros un dato que está en millas. Para ello, podríamos escribir el siguiente programa Python (puedes probar este programa en el Py-Libre teniendo la precaución de ingresar un dato cuando te imprima el mensaje “ingresa millas:”):
- Entrada: La primera instrucción (línea) da la orden para: imprimir en la pantalla el mensaje “ingresa millas:”, leer un dato desde el teclado (“input”) y luego guardarlo temporalmente en la memoria llamada “a”.
- Modelo/Proceso: La segunda instrucción dice que tome el dato almacenado en la memoria “a”, lo transforme en un número entero (“
int”) y luego lo guarde en la memoria “m”. La tercera instrucción dice que divida (“/”) el dato que está en “m” por el valor “0.62137” y guarde el resultado en la memoria “k”. - Salida: La última instrucción dice que imprima en la pantalla el mensaje “equivalente en kilómetros:” y el dato almacenado en la memoria “k”.
Cuando le ordenamos al computador que “ejecute” o “corra” estas instrucciones, ocurrirán las acciones que acabamos de describir (si es que las hemos escrito correctamente).
Hemos especificado estas instrucciones utilizando un “lenguaje de alto nivel” llamado Python. Podríamos haber utilizado otro lenguaje tal como Java, Perl, C++, C# o Visual Basic. Cada lenguaje de alto nivel viene con un software (llamado “compilador” o “intérprete”) que traduce las instrucciones escritas por nosotros a un “lenguaje de máquina” que es capaz de “entender” el procesador (CPU) del computador. Podríamos haber escrito las instrucciones directamente en el lenguaje de máquina para evitarnos la “traducción”, pero la verdad es que es demasiado complejo y aburrido incluso para los programadores más avanzados. Un lenguaje de alto nivel nos permite modelar y desarrollar software mucho más sofisticado y avanzado que el simple lenguaje de máquina.
Podríamos haber especificado las instrucciones directamente en castellano, pero necesitaríamos un “traductor” para que genere las instrucciones equivalentes en el lenguaje de máquina. La verdad es que el castellano así como el inglés o cualquier otro “lenguaje natural” es demasiado impreciso como para poder traducir a instrucciones tan específicas como las necesarias para que opere el computador. Si bien se desarrolla software para “traducir” instrucciones orales (audio) al lenguaje de máquina, en general se trata de instrucciones muy limitadas que permiten prender o apagar un celular, hacer algunas llamadas, escribir (más o menos) un texto y unas pocas cosas más, pero no permiten desarrollar programas sofisticados como los que veremos en este libro.
Python intenta acercarse lo más posible al inglés, sin perder la precisión necesaria para programar adecuadamente al computador. Por esta razón Python se conoce como un “lenguaje formal” (a diferencia de un “lenguaje natural”) al igual que los otros lenguajes computacionales antes mencionados.
En la figura 1.4 podemos ver una esquematización del funcionamiento de un traductor o compilador. El programa que escribimos en el lenguaje de alto nivel (como el del ejemplo 1.1) se conoce como el “código fuente”. El compilador toma como entrada dicho programa y genera un “código objeto” con las instrucciones de máquina para el procesador del computador. El procesador o ejecutor realiza las instrucciones recibidas y genera un resultado o salida de este proceso. El código objeto que se genera en la traducción se puede guardar y ejecutar todas las veces que queramos sin necesidad de volver a traducirlo. Cuando compras un juego de video, lo que instalas en tu computador es un código objeto que puedes ejecutar o correr todas las veces que quieras sin necesidad del código fuente. (El código fuente lo guarda el fabricante como protección de su propiedad intelectual.)
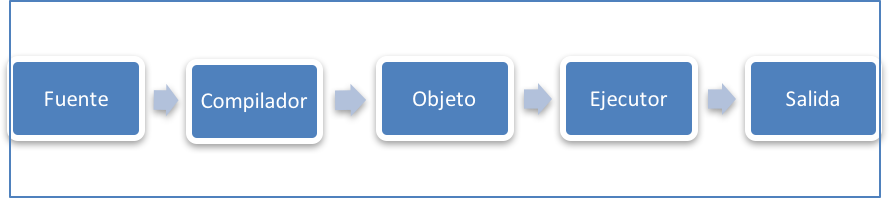
Existe una variante al funcionamiento de un compilador que se conoce como “intérprete”. Al igual que un compilador, el intérprete traduce de alto nivel a lenguaje de máquina pero no guarda un código objeto intermedio. Va haciendo la ejecución del programa directamente con cada instrucción. Si volvemos a ejecutarlo tiene que ser traducido nuevamente. Tiene la ventaja de dar retro-alimentación muy rápida al programador durante el proceso de desarrollo del software, pero se hace más lento para aplicaciones que ya están en fase de producción (como un juego de video comercial). En la figura 1.5 se muestra el esquema de funcionamiento de un intérprete.

Es importante notar que Python es un intérprete lo cual facilitará el trabajo para desarrollar tus programas, sobretodo porque posee herramientas de edición interactivas y de retro-alimentación inmediata, que te guiarán en tus labores de programación. (Si debes rendir pruebas de programación en papel y lápiz, te vas a lamentar de no tener acceso a esta característica tan útil de Python durante la examinación.)
Cuando instalas el Python en tu computador desde el sitio oficial (Python, 2016) también se instalará un editor (llamado IDLE) que facilitará la escritura de tus programas. Tanto el intérprete como el editor están disponibles gratuitamente para diversos sistemas operativos de computadores personales tales como Windows, MacOSX y Linux.
Puedes utilizar el editor de Python en dos formas distintas: modo interactivo o modo script. En el modo interactivo, el editor pone el símbolo >>> (llamado “chevron”) en la pantalla indicando que está listo para que ingreses algún dato o instrucción. A continuación de este símbolo puedes escribir alguna instrucción y luego pulsar la tecla enter para que se interprete y ejecute. Por ejemplo, prueba la siguiente instrucción en tu editor:
>>> 14 * 2
La respuesta que te dará el intérprete es 28, pues reconoce la instrucción como una multiplicación de los números enteros 14 y 2.
En el modo script puedes escribir un programa sin que se ejecute inmediatamente. Luego este código fuente se puede guardar en un archivo (el editor le agrega .py al nombre que le pones al archivo, así como el procesador de texto le agrega .docx a tus documentos Word). Posteriormente con el editor Python puedes abrir el archivo que contiene el código fuente y ejecutarlo.
1.6 Hardware: los “fierros” del computador¶
Es importante conocer un poco sobre los “fierros” o hardware del computador para que la programación sea productiva y eficiente. Al igual que un automóvil para el cual no necesitamos conocer los detalles del motor y otras piezas mecánicas para manejarlo y utilizarlo, tampoco necesitamos conocer los detalles del computador para sacarle provecho en muchas de sus funciones (por ejemplo acceso a Internet, escribir documentos Word o planillas Excel). Pero si queremos aprender a programarlo necesitamos conocer cómo funciona para comprender mejor los mecanismos básicos de los lenguajes de programación.
Hemos visto que los programas computacionales (software) se escriben en un cierto lenguaje y consisten en instrucciones que deberán ser ejecutadas por el procesador del computador. Este procesador se conoce como la unidad central de procesamiento o UCP (en inglés es CPU). La UCP es controlada por un software que se conoce como sistema operativo (SO). Dicho SO es el que recibe las instrucciones de nuestro programa y se encarga de que el procesador las ejecute. Por ejemplo, los computadores portátiles tienen sistemas operativos tales como Windows, MacOSX o LINUX. Los teléfonos inteligentes también tienen sistemas operativos que controlan sus distintas funciones, por ejemplo Android.
Además de la UCP, un computador tradicional tiene otros dispositivos de hardware tales como memoria principal o RAM, pantalla, teclado y ratón (“mouse”), memoria secundaria (discos duros o de estado sólido), unidad de comunicaciones (red cableada, Wi-Fi, BlueTooth), unidad lectora/escritora de discos CD o DVD y conectividad para dispositivos periféricos tales como impresoras, discos externos, memoria USB etc. Todos estos dispositivos tienen un software asociado llamado “driver” con instrucciones específicas para su funcionamiento. El sistema operativo de la UCP se comunica con los drivers de los dispositivos para ejecutar las instrucciones que le damos ya sea a través de un programa o directamente desde el teclado y/o ratón. En la figura 1.6 se muestra un esquema de los distintos dispositivos de un computador personal.
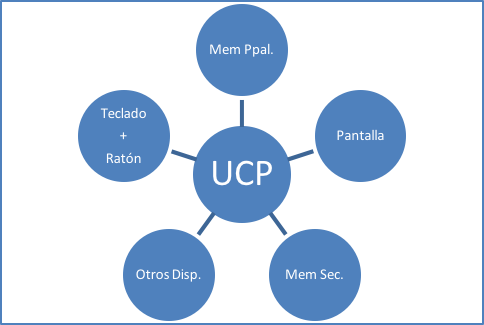
Siguiendo el esquema de la figura 1.1, podemos decir que el teclado y ratón son dispositivos de “entrada”, la UCP realiza el proceso de los datos y la pantalla es un dispositivo de “salida” donde se muestra el resultado del proceso. Una impresora también puede ser un dispositivo de salida. Si guardamos el resultado en el disco duro diremos que es de “salida”. Pero también podríamos leer datos de “entrada” desde el disco duro u otra memoria secundaria, como por ejemplo si escuchamos música desde un CD o vemos un video desde un DVD. Cualquier memoria secundaria se puede considerar como de entrada y/o de salida, Adicionalmente, la Internet que utilizamos a través de un dispositivo de comunicaciones podría servir de “entrada” o “salida” de datos. Si tenemos una pantalla táctil la podemos considerar de entrada y salida.
Es necesario ahora que nos detengamos un poco en la memoria principal o RAM dado que es un elemento fundamental para el funcionamiento del procesador y explica algunos de los conceptos básicos de la programación. No la hemos mencionado en el párrafo anterior dado que no se usa ni de entrada ni de salida de datos. Podemos comenzar diciendo que la UCP no puede procesar sin una RAM y mientras más pequeña sea la RAM más lento funcionará el computador. Veamos porqué.
La RAM es mucho más rápida y más cara que la memoria secundaria (esto es discos duros o estado sólido, memorias USB, CD, DVD, etc.), pero es muy limitada en su capacidad de almacenamiento. De hecho, la rapidez es directamente proporcional al costo lo cual limita fuertemente el espacio para guardar datos o programas. Además, la RAM es volátil, es decir, lo que está almacenado en ella se pierde cuando se termina de ejecutar el programa o cuando se apaga el computador. Por esta razón, los datos y programas que no deseamos perder los guardaremos en memoria secundaria.
Cuando escribimos un programa (en Python u otro lenguaje) es muy probable que lo guardemos en el disco duro o en una memoria USB. Pero para que (el sistema operativo de) la UCP pueda ejecutar las instrucciones del programa, el código (fuente si es intérprete, objeto si es compilador) debe estar almacenados en la memoria principal. El traspaso desde memoria secundaria a principal ocurre automáticamente (como una actividad comandada por el sistema operativo) cuando “abrimos” el programa y lo ejecutamos. La UCP no puede ejecutar el programa si este no está en la memoria principal. Dado que el espacio de la RAM es limitado, lo más probable es que el traspaso se haga por partes lo cual ralentiza la ejecución.
Algo similar ocurre con los datos de entrada que tal vez ingresamos desde el teclado o desde una pantalla táctil (también los podríamos leer desde una memoria secundaria). Estos datos son traspasados automáticamente (por el sistema operativo) a la memoria principal para que puedan ser utilizados por la UCP que está siendo “comandada” por nuestro programa. Cuando termina la ejecución del programa se pierden los datos (de entrada o salida) a no ser que (por instrucciones de nuestro programa) los guardemos en memoria secundaria.
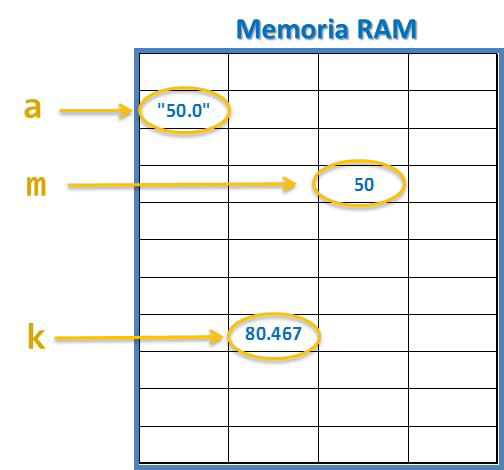
Si bien el traspaso del programa y los datos a la RAM es un proceso automático del cual no tenemos que preocuparnos, debemos encontrar alguna forma para referirnos a los datos y poder procesarlos. Aquí viene en nuestra ayuda el concepto de “variable” que es el mecanismo más básico de la programación. Visualicemos primero la memoria RAM como una estantería de pequeñas celdas separadas entre sí (como las utilizadas para guardar botellas de vino) y donde cada celda puede almacenar algún dato cualquiera. Una variable es un nombre que le damos a una celda en la RAM donde está almacenado algún dato. Esto se puede visualizar en la figura 1.7.
Veremos en el siguiente capítulo que las variables (o nombres de las celdas) las debes inventar tú en el rol de “programador”, y se pierden (o se borran igual que los datos) cuando termina la ejecución del programa. Python no trae nombres pre-definidos para las celdas de la memoria RAM.
En el ejemplo 1.1 hemos llamado “a” a la celda en memoria principal donde se almacena el dato que ingresamos desde el teclado. En el mismo ejemplo llamamos “m” y “k” a otras celdas de la RAM. Algunos autores explican esto diciendo que la variable “apunta” o “nos lleva” a la celda en la RAM donde está guardado (temporalmente) algún dato, tal como se ilustra en la figura 1.7 suponiendo que ingresamos “50.0” desde el teclado en la ejecución del programa del ejemplo 1.1. (La diferencia del dato en “a” y en “m” la veremos en el próximo capítulo.)
Con esto ya estamos preparados para que construyas tu primer programa en Python. Pero antes veremos el concepto de algoritmo que te ayudará a diseñar soluciones para problemas complejos y voluminosos. También revisaremos el concepto de depuración (“debugging”) que te guiará en el proceso de corregir los errores que se comenten en la programación.
1.7 Algoritmos¶
Los programas computacionales (software) se escriben en un cierto lenguaje (por ejemplo Python) y consisten básicamente en instrucciones (“código”) que deberán ser ejecutadas por el procesador tal como mostramos en el ejemplo 1.1. Pero cuando el problema o situación a representar es complejo y de mayor envergadura, no es recomendable ponerse a escribir el código sin haber pensado antes en un esquema o diagrama de solución. El concepto de algoritmo nos facilitará el desarrollo de una solución antes de escribir el programa.
Básicamente un algoritmo es como una receta de cocina donde se especifican ordenadamente los pasos a seguir (en nuestro caso en Español) para lograr el objetivo deseado. Por ejemplo, podríamos escribir un “algoritmo” con instrucciones para hacer una paella, o para sincronizar el celular con el BlueTooth del automóvil, o para instalar el decodificador de la TV por satélite, o para que un computador realice una determinada tarea.
Un algoritmo considera que el computador, al igual que un ser humano normal, puede hacer solo una acción a la vez. Esto se conoce como procesamiento secuencial. Entonces, al igual que en una receta, un algoritmo computacional indica los pasos secuenciales, desde el primero hasta el último, que deberá realizar el procesador del computador.
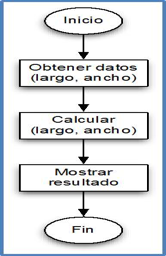
Por ejemplo, si nos piden hacer un programa para calcular el área de un rectángulo cualquiera, podríamos escribir un algoritmo como el que se muestra en la figura 1.8. Aquí suponemos que primero leemos los datos del problema, luego calculamos el área y finalmente mostramos el resultado. Es decir, seguimos el esquema sistémico de la figura 1.1 con una entrada, un proceso y una salida.

Ahora podemos escribir un programa Python que siga la lógica del algoritmo indicado en la figura 1.8. Este programa se muestra en el ejemplo 1.2. (Veremos el detalle de este programa en el siguiente capítulo.)
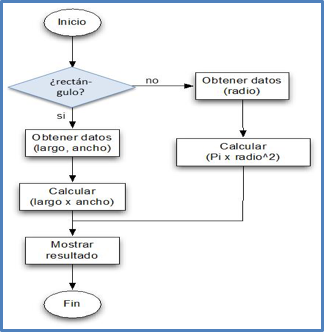
Existen diversas formas para escribir un algoritmo además de la secuencia de pasos que vimos en la figura 1.8. Por ejemplo, el formato de “diagrama de flujo” que se muestra en la figura 1.9 es también una buena forma de expresar un algoritmo. Veremos más adelante que este formato es muy útil cuando existen caminos alternativos (expresados con condicionales) a seguir en un proceso y también cuando hay que hacer varias repeticiones (ciclos) de una secuencia de instrucciones.
Por ejemplo, si nos piden un programa para calcular el área de un rectángulo o de un círculo, podemos escribir el algoritmo que se muestra en la figura 1.10. El programa Python correspondiente a este algoritmo lo veremos más adelante.
Es importante notar que los ejemplos mostrados corresponden a programas que ejecutan un paso o instrucción a la vez. Esto es en forma secuencial, un paso después de otro. Así serán todos los programas que veremos en este libro puesto que utilizaremos computadores de programación secuencial. No obstante, desde hace mucho tiempo existen también computadores con múltiples procesadores que pueden ejecutar varias acciones al mismo tiempo, una en cada procesador. Esto se conoce como procesamiento paralelo y existen lenguajes que permiten hacerlo. No lo veremos en este libro puesto que es bastante más complejo que la programación secuencial.
1.8 Depuración (“debugging”) de programas¶
Prontamente verás que es muy fácil equivocarse al escribir las instrucciones en un programa computacional, sea esto utilizando Python o cualquier otro lenguaje formal. Para que no sea muy frustrante, es importante que sepas que un buen porcentaje del trabajo a realizar estará justamente en la detección y corrección de los errores cometidos. Esto es porque la programación computacional es más un “arte” que una “ciencia”. Pero no te preocupes puesto que una de las mejores formas de aprender y disfrutarlo, es “construyendo”, “ensuciándose las manos” y cometiendo errores.
Debemos entonces transformar la frustración por los errores en un desafío para detectarlos y corregirlos. Esto implica en programación que debemos entender el problema que queremos resolver, diseñar un algoritmo o camino de solución, escribir un programa imperfecto (en nuestro caso en Python) y luego corregir los errores en forma iterativa (tanto en el diseño como en la programación) hasta que funcione bien. No buscaremos una solución óptima pero si intentaremos hacerlo lo mejor posible. No te olvides que lo “óptimo es enemigo de lo bueno”.
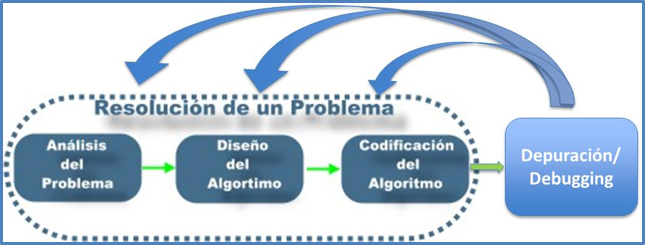
El proceso de solución de un problema mediante programación computacional conlleva las etapas que se muestran en la figura 1.11. Los errores en programación se conocen como “bugs” (bichos en español) y su corrección como “debugging” (limpieza, depuración, eliminación de bichos). Podemos considerar la depuración de los errores como un entretenido desafío intelectual.
A veces podemos cometer errores intencionales para entender mejor un proceso complejo o cuando no conocemos bien el funcionamiento de algunas instrucciones pre-definidas en Python. Esto es entonces un proceso experimental de prueba, error y corrección. En forma general podemos decir que existen tres tipos de errores de programación:
- Errores de Sintaxis: Estos errores ocurren cuando no escribimos en forma correcta algunas instrucciones pre-definidas de Python. Es equivalente a cometer errores de ortografía o gramaticales cuando escribimos en Español. En general, estos errores son detectados por el propio editor del Python, en el momento que estamos escribiendo el código. Esta detección automática se conoce como “parsing”. Cuando se detecta un error de este tipo, el programa no se puede ejecutar.
- Errores de Ejecución o “Run Time”: Estos errores son distintos a los de sintaxis y son detectados en el momento de ejecución del programa. Por ejemplo, el programa se podría quedar “pegado” en una secuencia de instrucciones repetitivas sin poder terminar correctamente. O podría generarse un error con un dato de entrada que no es lo que se esperaba para el proceso de cálculo o solución.
- Errores de Semántica: Estos errores son distintos a los de sintaxis y de ejecución. Generalmente ocurren cuando el programa se ejecuta correctamente, pero la solución del problema no es la que deseábamos puesto que el algoritmo estaba equivocado. Por ejemplo, calculamos un perímetro en vez de un área. Debemos entonces corregir el algoritmo.
En definitiva, deberás considerar que una buena parte de tu trabajo de programación estará en la depuración. Planifica tus tareas del curso de introducción a la computación con mucha anticipación, piensa bien en los algoritmos de solución, ármate de paciencia y déjate bastante tiempo para la depuración de los errores.
1.9 Resumen y glosario¶
Hemos revisado brevemente una serie de conceptos relativos a la programación y a las tecnologías de la información que esperamos te sirvan de motivación para estudiar en profundidad esta disciplina. Además de ser un tema muy entretenido, pensamos que se trata de herramientas fundamentales para apoyar las actividades de cualquier profesional o científico de la presente era. La depuración o “debugging” es fundamental para que el programa final funcione adecuadamente.
A continuación un glosario de los términos más relevantes.
- Compilador: Es un software que traduce las instrucciones escritas por nosotros en un lenguaje formal (código fuente), por ejemplo Python, a un programa en lenguaje de máquina (código objeto) que es capaz de “entender” el procesador (CPU) del computador.
- Intérprete: Es un software similar al compilador, con la diferencia que no genera un código objeto sino que ejecuta directamente cada instrucción de un programa o código fuente.
- Lenguaje Formal: es un lenguaje diseñado por el ser humano para cumplir funciones específicas, tales como la matemática, química y lenguajes computacionales.
- Lenguaje Natural: son los idiomas creados por los seres humanos tales como el español, inglés, francés y mapudungun. Evolucionan naturalmente con el uso y desuso que se les da.
- “Parsing”: revisión de la sintaxis (ortografía y gramática) de las instrucciones (o frases) en un programa, que es realizado en forma automática por el editor del lenguaje.
- Programa Computacional: Genéricamente conocidos como software, se escriben en un cierto lenguaje formal (por ejemplo Java o Python) y consisten básicamente en instrucciones que deberán ser ejecutadas por el procesador (CPU) de un computador.
- Semántica: Significado de una instrucción (o frase) de un programa computacional.
1.10 Referencias¶
- Mack, C. (2015). The Multiple Lives of of Moore’s Law. IEEE Spectrum Magazine, Abril 2015.
- Hey, T., Tansley S., Tolle K. (2009). The Fourth Paradigm, Data-Intensive Scientific Discovery. - Microsoft Research. Redmond, Washington, USA.
- Maloy, R. W., et al. (2014). Transforming Learning with New Technologies (2nd Edition). Pearson - Education Inc, New Jersey, USA.
- Miller, B., Ranum D. (2016). Runestone Interactive. http://interactivepython.org/
- Python (2016). Python Software Foundation. https://www.python.org/
- Steen M., Van de Poel I. (2012). Making Values Explicit During the Design Process. IEEE Technology and Society Magazine, Vol. 31, N° 4.
- Woolf, B. P. (2008). Building Intelligent Interactive Tutors: Student Centered Strategies for Revolutionizing e-Learning. Morgan Kaufmann Publishers, Burlington, MA, USA.
- Referencias de HCI.